MatSpray
Fusing 2D Material World Knowledge on 3D Geometry
MatSpray — Better relightable 3D objects by using 2D material world knowledge.
Overview
We propose MatSpray, a framework for fusing 2D material world knowledge from diffusion models into 3D geometry to obtain relightable assets with spatially varying physically based rendering (PBR) materials. Our method leverages pretrained 2D diffusion-based material predictors to generate per-view material maps (base color, roughness, metallic) and integrates them into a 3D Gaussian Splatting representation via Gaussian ray tracing. To enhance multi-view consistency and physical accuracy, we introduce a lightweight Neural Merger that refines material estimates using a softmax-based restriction. Our approach enables high-quality relightable 3D reconstruction that outperforms existing methods in both quantitative metrics and visual realism, while being approximately 3.5× faster than state-of-the-art inverse rendering approaches.
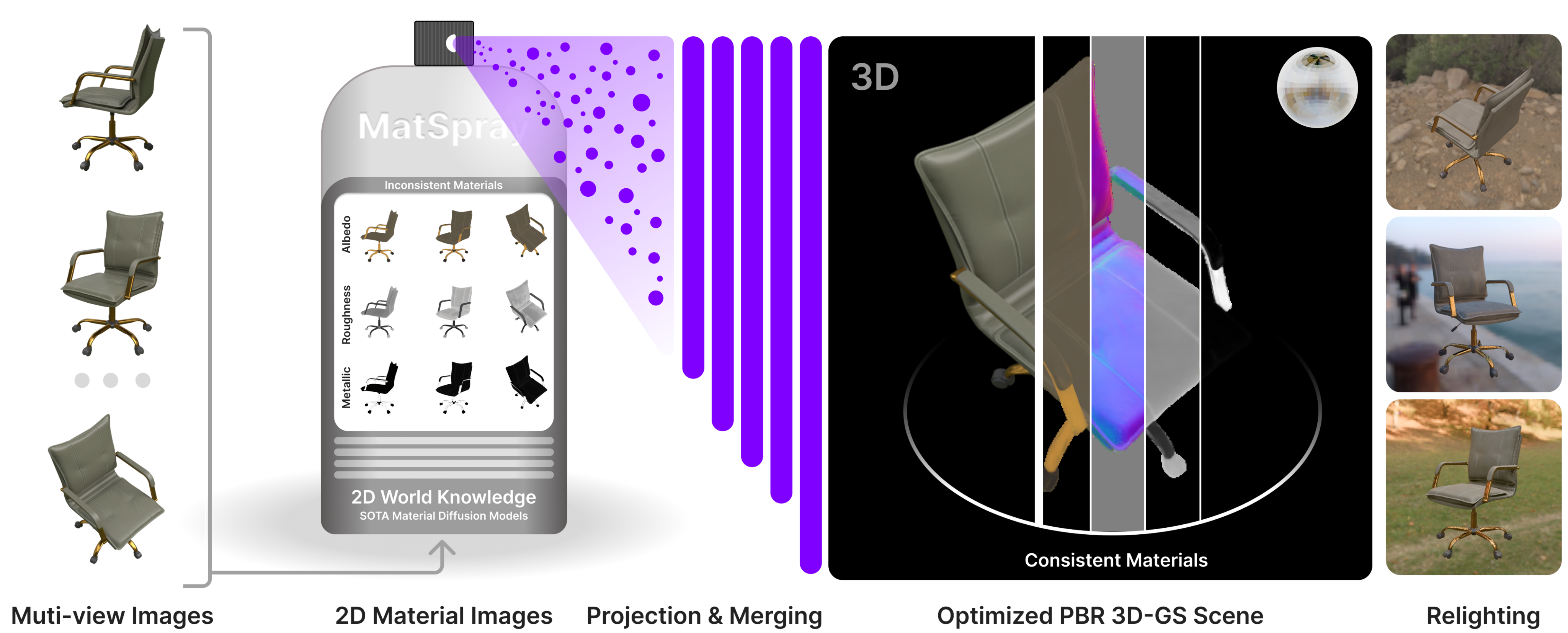
Pipeline
MatSpray combines 2D diffusion predictions with 3D Gaussian geometry to recover consistent, relightable PBR materials. Our pipeline begins by generating per-view material maps using any diffusion-based material predictor (we use DiffusionRenderer in our experiments). The scene geometry is reconstructed via relightable Gaussian Splatting, providing both geometry and normals. The 2D material estimates are then transferred to 3D using Gaussian ray tracing, which projects material values from pixels to Gaussians based on their projected footprints. To resolve multi-view inconsistencies inherent in 2D predictions, we introduce the Neural Merger—a lightweight MLP with softmax output that aggregates per-view material estimates per Gaussian. The merged materials are refined through dual supervision: material maps are supervised against the 2D diffusion predictions, while deferred PBR rendering is supervised against ground-truth images with an optimizable environment map.
Results
MatSpray achieves superior relighting quality and material estimation compared to state-of-the-art methods. We evaluate against an extended version of R3DGS and IRGS on both synthetic and real-world datasets. Our method produces cleaner base color maps with minimal baked-in lighting, more accurate metallic predictions, and improved roughness estimation. Quantitative results show consistent improvements across PSNR, SSIM, and LPIPS metrics, with particularly strong performance on specular and metallic objects. The approach is approximately 3.5× faster than IRGS, requiring only 25 minutes per scene on average.
Relighting Quality — Our method produces relighting results that closely match ground truth, particularly for specular objects. Unlike R3DGS which struggles with unconstrained material optimization, MatSpray constrains materials through the Neural Merger, enabling more accurate environment map optimization. IRGS exhibits artifacts such as floaters and overly flat surfaces, while our approach maintains geometric detail and accurate material properties across both diffuse and specular surfaces.
Material Maps — MatSpray effectively removes baked-in lighting effects from base color maps, producing nearly diffuse albedos with minimal shadowing. The Neural Merger significantly enhances multi-view consistency compared to raw DiffusionRenderer predictions, which exhibit view-dependent variations. Our metallic maps match ground truth substantially better than competing methods, and roughness estimation benefits from enforced view consistency, resulting in more physically plausible parameters.
Real-World Results — On real-world objects, MatSpray demonstrates consistent, high-quality reconstructions. Our method produces locally sharp and coherent base colors across surfaces, while baselines exhibit noise, distortions, or view-dependent artifacts. The relighting results show that our predicted materials generalize well across different lighting conditions, maintaining physical accuracy without baking illumination into the material properties.

Ablation Study
Our ablation study demonstrates that the Neural Merger is the key component responsible for superior performance. The full model achieves the highest scores across all metrics, significantly outperforming variants without the Neural Merger. The softmax normalization in the Neural Merger is crucial—without it, the network encodes lighting and shadow patterns into materials, leading to view-dependent inconsistencies and degraded relighting quality.

Neural Merger Analysis — The Neural Merger's softmax-based weighting mechanism prevents the network from freely generating new material values, instead interpolating between diffusion predictions. This ensures merged results remain consistent with world knowledge captured by diffusion priors while enforcing coherence across views. Without softmax normalization, shadows from input images leak into base color maps, and renderings become blurry in high-detail areas. The softmax layer is not merely a numerical improvement but a key component ensuring robustness and preventing view-dependent appearance encoding.

Citation
More Information
Open Positions
Interested in persuing a PhD in computer graphics?
Never miss an update
Join us on Twitter / X for the latest updates of our research group and more.
Recent Work
Acknowledgements
Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy – EXC number 2064/1 – Project number 390727645. This work was supported by the German Research Foundation (DFG): SFB 1233, Robust Vision: Inference Principles and Neural Mechanisms, TP 02, project number: 276693517. This work was supported by the Tübingen AI Center. The authors thank the International Max Planck Research School for Intelligent Systems (IMPRS-IS) for supporting Jan-Niklas Dihlmann.